Formation of chains of sparse distributed codes in a macrocolumns
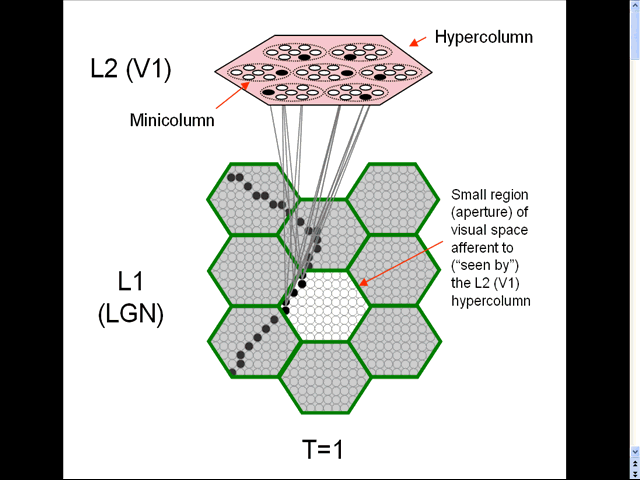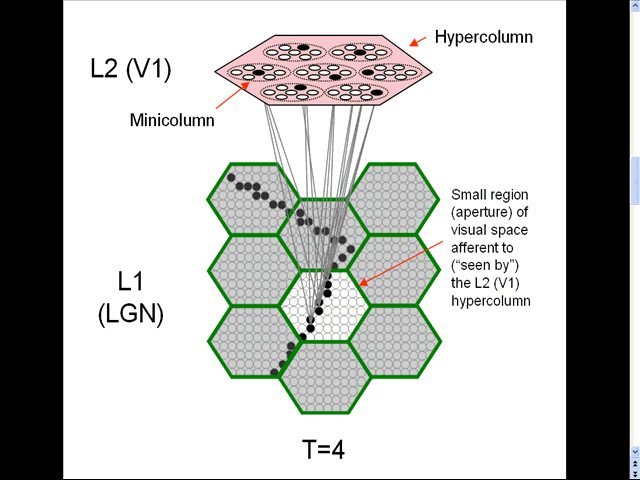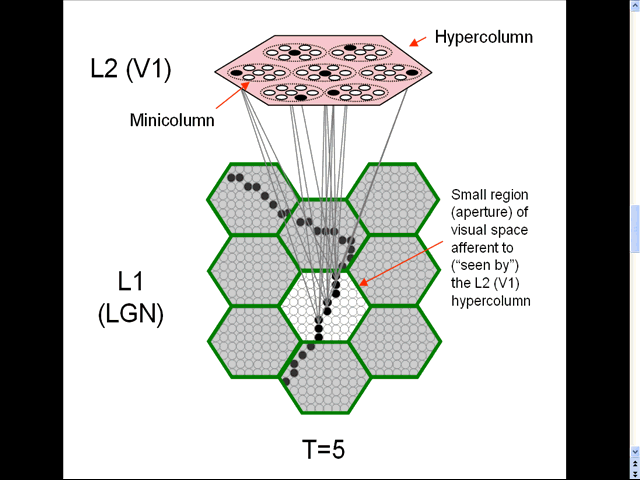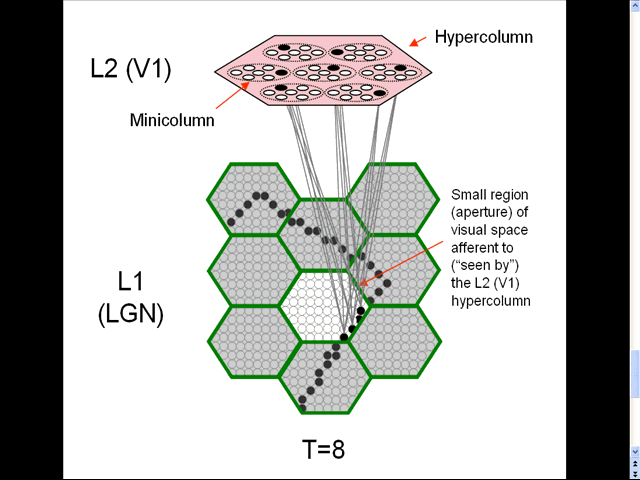
- The animation shows a sequence of spatial inputs (frames) over a small region of the visual field, as notionally represented in the LGN.
- The sequence corresponds to a corner of a rectangle passing through the region.
- On each frame, an L2 code, which is a sparse distributed code (SDC), consisting of one active neuron (black) in each of the Q=7 minicolumns, is activated [chosen by the Code Selection Algorithm (CSA): described in 1996, 2010, 2014, 2017 and on this page.] in the V1 hypercolumn (macrocolumn) (pink) that sees the central (white) aperture.
- This tiny macrocolumm instance consists of only Q=7 minicolumns, each containing only K=7 principal neurons (which we take to correspond to the layer 2/3 pyramidals). However, real neocortical macrocolumns consists of Q~70 minicolumns, each with K~20 layer 2/3 pyramidals; V1 macrocoolumns (hypercolumns) may be about twice as large.
- On each frame, the active L1 (LGN) code (which is not a sparse distributed code) is associated in the bottom-up (U) and top-down (D) directions with the L2 code that becomes active. Only a tiny sample of these vertical (U or D) associations are shown (gray lines).
- In addition, the L2 neurons connect, via a horizontal synaptic matrix, to all other L2 neurons in the same and nearby macrocolumns (with distance-dependent fall-off of connectivity rate). These horizontal connections are not shown here but are shown in many other figures/animations throughout this website, e.g., Figs. 2,3 here, Figs. 2,3 here, and Fig. 2 here.
- The L2 codes are chained together. Specifically, the neurons comprising the L2 code active at T increase their weights onto the neurons comprising the L2 code that becomes active at T+1.
- Thus, we see (if we visualize the horizontal weight increases) the formation of a sparse distributed spatiotemporal memory trace in this particular macrocolumn in response to the occurrence of a natural space-time pattern (moving edge).
- In the real brain, this scenario would be taking place in the context of a much larger network with many more hierarchical levels, corresponding to the progression of visual cortical areas along the ventral and dorsal pathways. This animation shows a slightly more complex scenario. There is simultaneous learning at multiple macrocolumns across the hierarchical stages. Cells (and therefore the sparse distributed codes that they comprise) at higher cortical stages have larger spatial receptive fields (RFs), due to the accumulative effects of fan-in/fan-out accumulating across the prior stages (e.g., shown here) and larger temporal RFs, due to longer activation durations (persistences) of codes (e.g., shown here), for which there is substantial evidence (cf., Uusitalo et al, 1996; Hasson et al., 2008, and the huge working memory literature).
- The longer persistence of a code at level J allows/causes it to associate with multiple successive codes at level J-1 (effecting a hierarchical temporal nesting). This implements a chunking mechanism of sequence learning, and thus, of compression.
- Note: the partitioning of LGN (green hexagons) is effected by the pattern of feedforward and feedback connections from V1. These (green) borders are therefore not really abrupt as shown here. Also, the borders between the V1 hypercolumns are not really abrupt either. These simplifications are just to facilitate explanation; the underlying theory allows overlapping hypercolumns (and in fact, minicolumns) as well as overlapping LGN regions.