Sparsey Information Storage Capacity Study:
Study 3: Exact-match natural-derived Sequence Recognition
Studies 1 and 2 involved random sequences. In this study, we will characterize storage capacity for the exact-match test condition using sequences derived from natural video by edge-filtering and binarization. Figure 5 shows a few of the natural-derived sequences used Study 3. All of the natural-derived sequences were produced by extracting a 12x12 pixel window from 10-frame subsequence of a processed version of one of the Hollywood 2 video snippets.
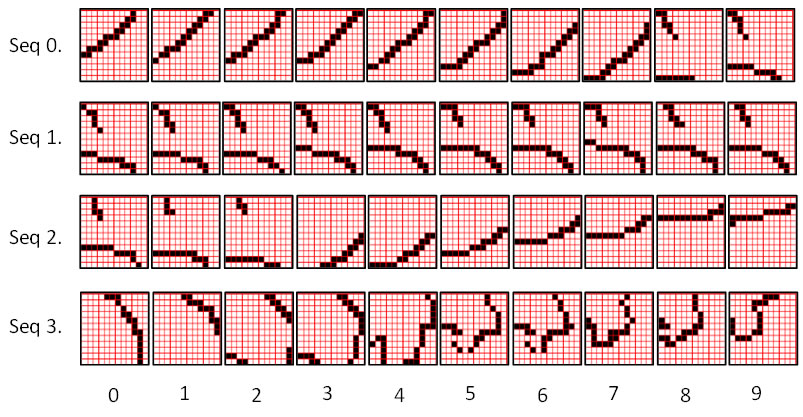
Figure 5: Four of the 10-frame natural-derived sequences used in Study 3.
The same basic pattern of capacity scaling can be seen in Table 5 as in the previous studies: absolute capacity grows with network size while bits/synapse seems to trend downward. We consider the primary finding of this study to be that the absolute capacities for these natural-derived sets of sequences, which contain very high amounts of correlation (redundancy), is still quite appreciable. This provides preliminary basis for optimism that SparseyR’s storage capacity will scale well for naturalistic inputs.
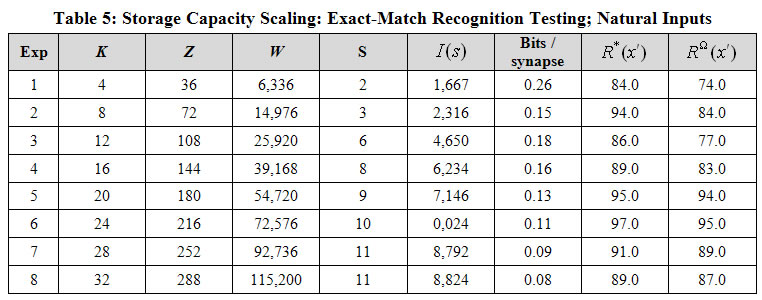
Figure 6 shows the pair-wise intersections (similarities) of the L1 codes assigned (learned) in one run of Experiment 1 of Study 3. The same general remarks apply here as for Figure 4, except that this Study was an exact-match study. Thus, the test presentations were identical to the training presentations. Reading down the minor diagonal (between the red lines), one can see that while the model makes some unit-level mistakes from frame to frame, e.g., achieving 7 or 8 out of 9 correct units, accuracy averaged over all frames was quite high for both sequences. The self-correction through time can also be seen in that as one moves down that minor diagonal, accuracy often recovers, e.g., from 7 of 9 correct to 8 of 9 and then up to 9 of 9.
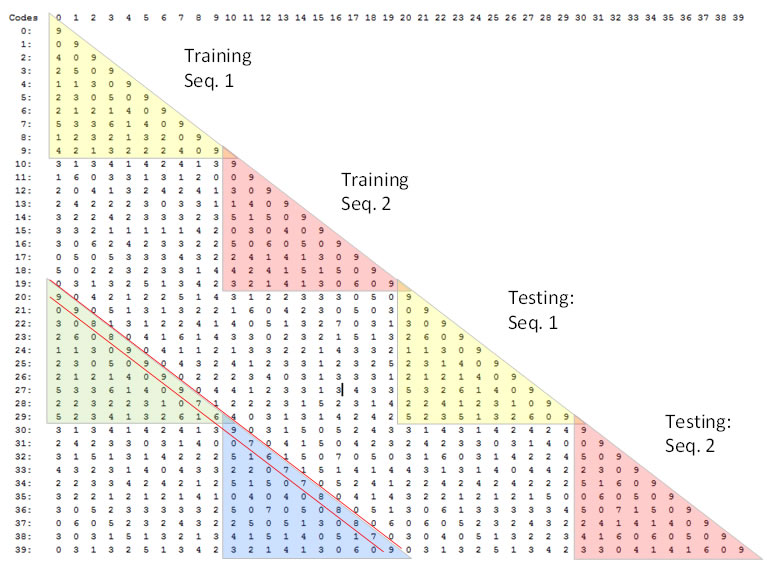
Figure 6: Pair-wise intersections of the L1 codes assigned in one run of Experiment 1 of Study 3.